서론
Instacart Market Basket Analysis는 기업측에서 제공한 고객의 실제 구매 데이터를 이용한 프로젝트가 가능하기 때문에 이 프로젝트를 진행하게 됐습니다.
무엇보다 Instacart는 올해 하반기 미국 주식시장 상장을 앞두고 있기 때문에 더 이 프로젝트에 눈이 갔습니다.
이 프로젝트의 목적은 Instacart 측에서 제공한 데이터를 바탕으로 고객들의 물품 재구매를 예측하는 것입니다.
재구매 예측을 위해서는 EDA를 통해 재구매와 상관관계가 있는 데이터를 구하는 과정이 선행되어야 합니다.
이번 프로젝트는 재구매와 상관관계가 있는 데이터를 탐색하는 과정이라고 보면 됩니다.
우선 탐색적 데이터 분석을 위해 세가지 단계를 따라가려고 합니다.
- 데이터셋 확인
- 데이터셋에서 얻을 수 있는 정보 추론
- 탐색적 데이터 분석
데이터 셋 확인
1. aisles
aisles는 세부 제품류 및 세부 제품류 번호를 나타내는 데이터입니다.
나중에 나올 products, orders와 merge해서 주문 데이터의 세부 제품명 및 제품류를 분석할 때 쓰일 것입니다.
| aisle_id | aisle | |
|---|---|---|
| 0 | 1 | prepared soups salads |
| 1 | 2 | specialty cheeses |
| 2 | 3 | energy granola bars |
| 3 | 4 | instant foods |
| 4 | 5 | marinades meat preparation |
2. departments
departments 역시 aisles처럼 대 제품류를 나타내는 데이터입니다. products, orders와 대조해서 어떤 제품을 구매했는지 확인할 수 있는 데이터입니다.
나중에 어떤 제품류를 재주문하고 재주문율이 어떻게 되는지 분석할 수 있는 데이터입니다.
| department_id | department | |
|---|---|---|
| 0 | 1 | frozen |
| 1 | 2 | other |
| 2 | 3 | bakery |
| 3 | 4 | produce |
| 4 | 5 | alcohol |
3. products
products는 제품 번호와, 제품명, aisle번호, department 번호 등이 있습니다.
aisle_id와 department_id가 있기 때문에 aisles와 departments를 연계해서 분석할 수 있습니다.
그래서 나중에 어떤 제품이 재구매되고 재구매율이 어떻게 되는지 분석할 때에 쓰입니다.
| product_id | product_name | aisle_id | department_id | |
|---|---|---|---|---|
| 0 | 1 | Chocolate Sandwich Cookies | 61 | 19 |
| 1 | 2 | All-Seasons Salt | 104 | 13 |
| 2 | 3 | Robust Golden Unsweetened Oolong Tea | 94 | 7 |
| 3 | 4 | Smart Ones Classic Favorites Mini Rigatoni With Vodka Cream Sauce | 38 | 1 |
| 4 | 5 | Green Chile Anytime Sauce | 5 | 13 |
4. orders
각 주문의 고객, 주문 순서, 요일, 시간, 전 주문으로부터 기간 을 담은 데이터입니다.
eval_set 칼럼에 마지막 주문은 train 그것을 제외한 모든 주문은 prior라고 입력되어 있어서 세부 주문 정보는 두개의 파일로 나뉘는 것을 알 수 있습니다.
그리고 order_id는 order_products_prior, order_products_train의 칼럼과 겹치기 때문에 두 파일과 연계해서 사용할 수 있습니다.
마지막으로 시간 정보가 담겨있기 때문에 시간에 대한 분석이 가능한 데이터입니다.
| order_id | user_id | eval_set | order_number | order_dow | order_hour_of_day | days_since_prior_order | |
|---|---|---|---|---|---|---|---|
| 0 | 2539329 | 1 | prior | 1 | 2 | 8 | NaN |
| 1 | 2398795 | 1 | prior | 2 | 3 | 7 | 15.0 |
| 2 | 473747 | 1 | prior | 3 | 3 | 12 | 21.0 |
| 3 | 2254736 | 1 | prior | 4 | 4 | 7 | 29.0 |
| 4 | 431534 | 1 | prior | 5 | 4 | 15 | 28.0 |
| 5 | 3367565 | 1 | prior | 6 | 2 | 7 | 19.0 |
| 6 | 550135 | 1 | prior | 7 | 1 | 9 | 20.0 |
| 7 | 3108588 | 1 | prior | 8 | 1 | 14 | 14.0 |
| 8 | 2295261 | 1 | prior | 9 | 1 | 16 | 0.0 |
| 9 | 2550362 | 1 | prior | 10 | 4 | 8 | 30.0 |
| 10 | 1187899 | 1 | train | 11 | 4 | 8 | 14.0 |
| 11 | 2168274 | 2 | prior | 1 | 2 | 11 | NaN |
| 12 | 1501582 | 2 | prior | 2 | 5 | 10 | 10.0 |
| 13 | 1901567 | 2 | prior | 3 | 1 | 10 | 3.0 |
| 14 | 738281 | 2 | prior | 4 | 2 | 10 | 8.0 |
| 15 | 1673511 | 2 | prior | 5 | 3 | 11 | 8.0 |
| 16 | 1199898 | 2 | prior | 6 | 2 | 9 | 13.0 |
| 17 | 3194192 | 2 | prior | 7 | 2 | 12 | 14.0 |
| 18 | 788338 | 2 | prior | 8 | 1 | 15 | 27.0 |
| 19 | 1718559 | 2 | prior | 9 | 2 | 9 | 8.0 |
5. order_products_prior
order_products_prior은 orders 데이터와 대조하여 각 주문들이 어떤 제품이고 몇번째로 장바구니에 추가되었고, 마지막으로 재주문 여부를 알려주는 데이터입니다.
orders 및 products 데이터와 연계하면 분석이 가능합니다.
| order_id | product_id | add_to_cart_order | reordered | |
|---|---|---|---|---|
| 0 | 2 | 33120 | 1 | 1 |
| 1 | 2 | 28985 | 2 | 1 |
| 2 | 2 | 9327 | 3 | 0 |
| 3 | 2 | 45918 | 4 | 1 |
| 4 | 2 | 30035 | 5 | 0 |
6. order_products_train
order_products_train 역시 orders 데이터와 대조하여 각 주문들이 어떤 제품이고 몇번째로 장바구니에 추가되었고, 마지막으로 재주문 여부를 알려주는 데이터입니다.
orders 및 products 데이터와 연계하면 분석이 가능합니다.
| order_id | product_id | add_to_cart_order | reordered | |
|---|---|---|---|---|
| 0 | 1 | 49302 | 1 | 1 |
| 1 | 1 | 11109 | 2 | 1 |
| 2 | 1 | 10246 | 3 | 0 |
| 3 | 1 | 49683 | 4 | 0 |
| 4 | 1 | 43633 | 5 | 1 |
데이터 셋으로 할 수 있는 분석 추론
Kaggle에서 제공받은 데이터들을 기반으로 분석할 수 있는 것들을 추론해보겠습니다.
크게 제품, 제품류, 시간과 관련된 분석이 가능하다고 보입니다.
- 어떤 제품이 재구매율이 높나요?
- 어떤 제품이 가장 많이 구매되나요?
- 어떤 제품이 가장 많이 재구매되나요?
- 어떤 제품류가 재구매율이 높나요?
- 몇번째로 카트에 추가한 제품이 재구매율이 높나요?
- 재구매하는 사람들의 재구매하는 시간적 간격이 어떻게 되나요?
- 몇 시쯤에 많이 구매하나요?
- 며칠 후 그리고 몇시 쯤에 많이 다시 구매하나요?
- 고객별 주문 횟수 및 주문 제품 갯수는 어떻게 되나요?
- 주문 횟수의 고객 분포는 어떻게 되나요?
탐색적 데이터 분석
어떤 제품이 재구매율이 높나요?
- productsCount라는 첫구매 재구매 상관없이 구매된 횟수를 보여주는 DataFrame을 만듭니다.
- orders_products_prior_df의 'product_id' 칼럼에서 id별 개수를 구하고
- 위에서 구한 데이터로 개수(count)와 제품 번호(product_id) 칼럼으로 구성된 DataFrame(productsCount)을 만듭니다.
- productsCount과 product_df를 'product_id'를 기준으로 합칩니다.
- 위의 데이터프레임에서 제품별 주문 횟수를 구하는 데이터를 구할 수 있습니다.(상위30개)
- 우선 주문 데이터에서 재구매(reordered)된 제품번호을 구하고 제품번호별로 그룹화합니다.
- 그리고 재구매된 횟수(reordered_count)와 제품 번호(product_id)로 칼럼을 구성합니다.
- 위에서 구한 데이터프레임과 'product_id'를 기준으로 합칩니다.
- 제품별 재구매 횟수 / 총구매 횟수 = 재구매율 을 구하고 재구매율 칼럼을 만듭니다.
- 위의 데이터프레임과 product_df 를 합쳐 제품명을 데이터프레임에 넣습니다.
- 위에서 구한 데이터프레임으로 제품별 재구매율 및 재구매 횟수등을 분석할 수 있습니다.
단순히 총주문량과 재주문량만 따졌을 때는 'Banana'와 'Bag of Organic Bananas'가 양이 압도적으로 많습니다.
재주문율이 압도적으로 높은 'Raw Veggie Wrappers', 'Serenity Ultimate Estrema Overnight Pads'은 주문량이 상위 30위에도 못 드는 것을 알 수있습니다.
재주문으로 직접적으로 연결되는 데이터인 재주문율과 주문량은 큰 상관관계가 없는 것을 알 수 있습니다.
물론 재주문량이 많은 제품들도 재주문율이 낮은 편이 아니지만, 재주문하는 것을 예측하기 위해선 재주문율 데이터가 중요하다고 보여집니다.
나중에 제품류별로 분석할 때 다시 확인하겠지만, 주문량이 많은 제품류, 재주문율이 유독 높은 제품류가 직관적으로 확인됩니다.



어떤 제품류가 재주문율이 높나요?
- 제품류도 주문 데이터와 분리되어 있기 때문에 데이터프레임 합치는 작업을 진행합니다.
- 재구매 데이터프레임과 제품 데이터프레임을 'product_id'기준으로 합칩니다.
- 그리고 aisles 데이터프레임을 'aisles_id'기준으로 합치고 또 합친 데이터프레임을 departments 데이터프레임과 'department_id'를 기준으로 합쳐줍니다.
- 그리고 여기서 얻은 데이터로 재구매율이 높은 제품류를 분석합니다.
- 여기서 reordered는 0과 1로 이루어져 있어서 의 평균값은 재구매율과 같게 됩니다.
가장 재주문율이 높은 제품류는 계란및유제품류(diary eggs), 음료류(Beverage), 농산물(Produce), 빵류(Bakery) 등입니다.
위에서 봤던 'Raw Veggie Wrappers', 'Serenity Ultimate Extrema Overnight Pads' 같은 개별 상품들은 상품 특성상 제품류에 비해 유독 재주문율이 높습니다.
그리고 주문량이 많았던 'Banana'나 'organic whole milk' 같은 농산물류, 유제품류가 가장 재주문율이 높은 것을 확인 할 수 있습니다.
미용(Personal Care)이나 부엌제품(pantry), 국제(international) 제품류는 위의 제품류들보다 재구매와 상대적으로 연관이 적다고 볼 수 있습니다.

몇번째로 장바구니에 추가한 주문의 재주문율이 높을까요?
- 70번째 이상으로 장바구니에 추가한 경우는 무시할만하기 때문에 70번째 이상의 'add_to_cart_order'는 모두 70으로 처리합니다.
- 그리고 이 데이터프레임도 역시 'reordered' 값이 1이면 재주문 0이면 첫 주문이기 때문에 평균값이 곧 재주문율입니다.
- 그래프를 만들어줍니다
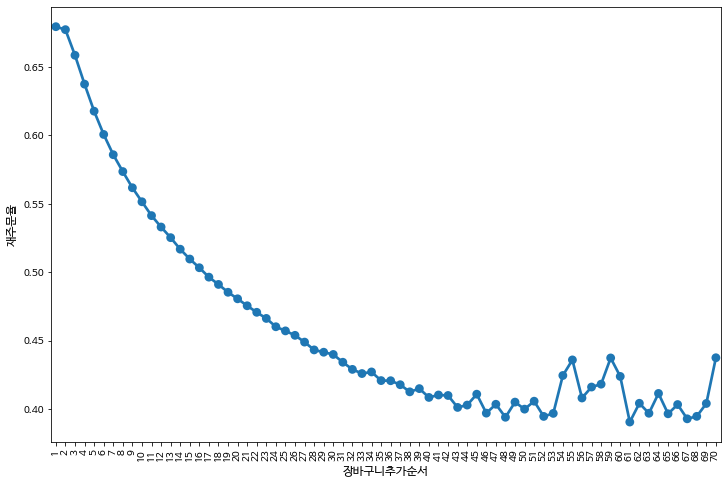
아래 그래프는 장바구니에 추가한 순서는 x축 재구매율은 y축으로 표현한 그래프입니다.
장바구니에 추가한 순서와 재구매율은 반비례한다는 추세를 그래프를 통해 확인할 수 있습니다.
첫번째 추가한 주문에서 가장 재구매율이 높았고 나중에 추가한 주문일수록 낮아지는 것을 확인할 수 있습니다.
그러므로 몇 번째로 장바구니에 추가했는지의 데이터는 재구매와 상관관계가 높은 데이터로 볼 수 있습니다.
재주문하는 시간적 간격이 어떻게 되나요?
- orders_df에서 'days_since_prior_order 칼럼의 정보로 그래프 만들기
아래 그래프는 전 주문으로부터 날짜 간격을 보여줍니다.
30일 이상의 간격은 모두 30으로 표현했기 때문에 30일이 가장 높게 나오니까 30일을 제외하면 7일 간격이 가장 큰것으로 보입니다.
그리고 일주일 내의 간격이 가장 많은 것을 확인할 수 있고 대체적으로 7일이 지나면 완만하게 그 수가 줄어드는 것을 확인할 수 있습니다.
날짜 간격이 늘어나면서 주문량이 줄어드는 중에 14일, 21일, 28일은 그 수가 일시적으로 늘어나는 것을 확인할 수 있습니다.
결론적으로 일주일 이하의 간격으로 재주문하는 경우가 많고 일주일 단위로 혹은 7의 배수의 날짜 간격으로 재주문하는 경향이 있다는 것을 알 수 있습니다.

제품군 별로 재주문하는 간격이 어떻게 되나요?
- order_products_*, products, departments, orders 를 합친 데이터프레임을 만든다.
- for문으로 모든 department의 days_since_prior_order 별 order_number를 count한다.
- for문으로 countplot을 만든다.
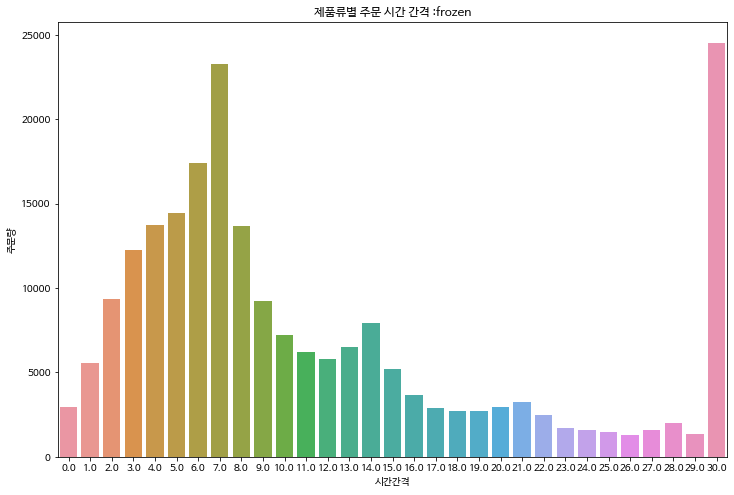
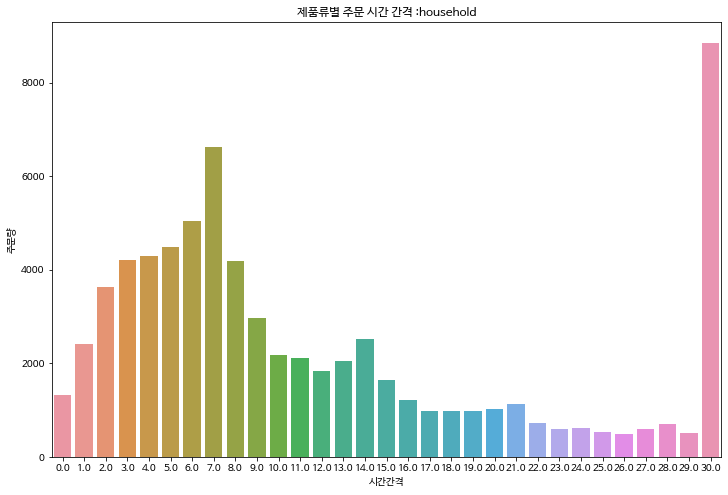
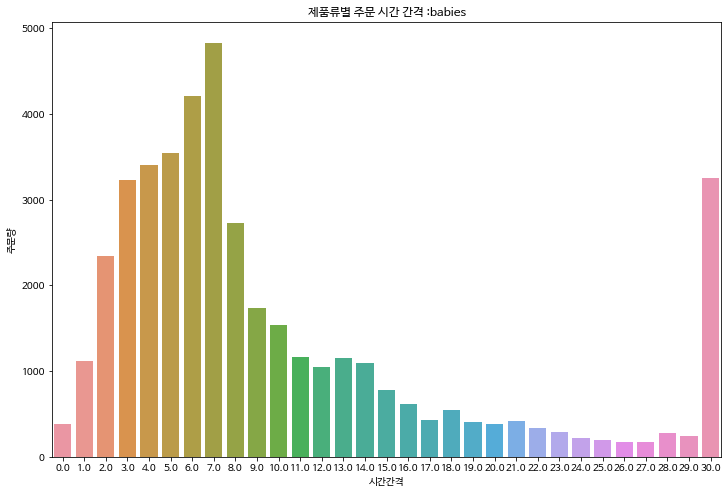
제품류 별로 days_since_prior_order를 분석하면 대체적으로 다 비슷한 경향을 띈다.
7일 전까지 주문량이 계속 늘다가 시간이 지날수록 주문량이 줄어들고 일주일 간격으로 국지적인 상승이 일어난다.
그러나 'household', 'daily care'같이 상대적으로 재주문율이 낮은 제품류는 7일차에 늘어나는 기울기가 상대적으로 작다.
제품류중 특이하게 'alcohol'은 재구매 간격이 짧고, 7일이 되더라도 늘어나는 정도가 작은 것을 확인할 수 있다.


















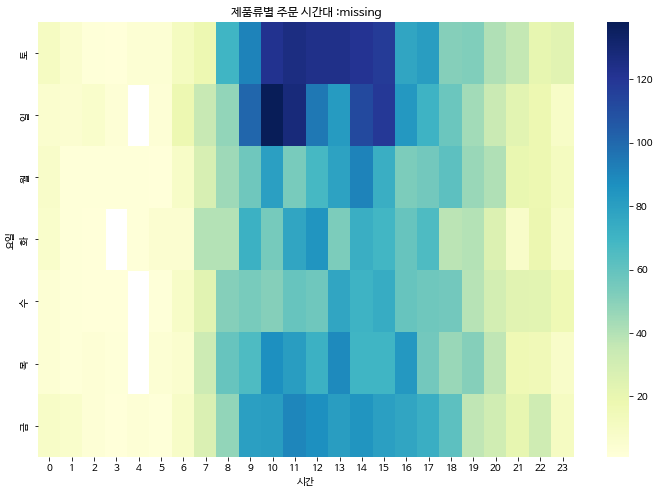
제품류 별로 주문되는 시간은 어떻게 되나요?
위의 분석과 비슷한 맥락의 정보를 얻을 수 있습니다.
'produce', 'dairy egg' 등과 같이 재주문율이나 재주문량이 많은 제품류는 주문이 주말에 집중되는 경향을 보입니다.
그러나 'household', 'bulk' 같이 재주문율이 낮은 제품류는 평일에도 주문량이 비교적 균등하게 분포되어 있습니다.
역시 'alcohol' 은 주중의 피로가 쌓인 수요일, 목요일 낮에 주문이 집중되는 경향을 보입니다.




















결론
첫번째 분석
주문량이 항상 재주문율과 비례하지는 않습니다.
주문량이 많은 제품이 대체적으로 재주문율도 높지만 가장 주문량이 많은 제품이 가장 재주문율이 높지도 않습니다.
둘 사이의 약한 상관관계가 있는 것 같습니다.
그래도 첫번째 분석은 어느 제품이 재주문으로 이어지는지 알 수 있게된 분석입니다.
두번째 분석
제품류별로 봤을 때 재주문으로 이어지는 제품류의 경향을 읽을 수 있습니다.
첫번째 분석과 비교했을 때 특정 제품들은 제품이 속한 제품류의 경향을 따라가지 않는 것을 확인할 수 있었습니다.
세번째 분석
세번째 분석은 수치적으로 재구매율과 상관관계를 구할 수 있는 분석입니다.
장바구니에 추가한 순서가 이를수록 재구매하는 비율이 높다는 것을 확인할 수 있기 때문입니다.
네번째 분석
대체적으로 대부분의 상품들이 재주문 간격이 일주일째가 될때까지 서서히 주문량이 많아집니다.
간격이 길어질수록 점점 주문이 줄지만 일주일 간격으로 일시적 상승이 있습니다.
하지만 몇 제품류는 이 경향에서 벗어났습니다.
재주문율이 낮은 'household', 'daily care'는 주문량이 늘어나는 기울기가 낮고 주말에 주문량이 주말에 집중되지 않는 경향이 있습니다.
'alcohol'의 경우 구매 간격일수가 적을수록 주문량이 많습니다.
무엇보다 'alcohol'은 다른 제품류와는 달리 평일에 주문이 집중되는 경향이 있습니다.
https://github.com/zizilnam/K-Digital_Training/blob/main/toyproject_EDA_.ipynb
'AI > K-Digital Training' 카테고리의 다른 글
| 016. 머신러닝 공부 시작 소감 및 반성문 (0) | 2021.09.03 |
|---|---|
| 015. K-Digital Training 7-8월 월간 리뷰 (0) | 2021.08.19 |
| 013. 데이터 베이스 개념 요약 2 (0) | 2021.08.09 |
| 012. 데이터베이스 개념 요약1 (0) | 2021.08.09 |
| 011. 네이버 증권에서 내 주식 뉴스 데이터크롤링 (0) | 2021.08.07 |