제목부터 총체적 난국입니다.
영어만 쓰여있는 데다가 약어로 쓰여있어서 도대체 무슨 말이지 싶습니다.
저번 글에서 이번 글은 차원 축소 및 word2vec에 대해 다룬다고 했었는데 살짝 힘들게 되었습니다.
최근 실무에서는 word2vec은 옛날 기술이 되고 TF-IDF가 더 익숙한가 봅니다.
TF-IDF도 금방 옛날 기술이 되겠지요..
저번 글에서 NLP Workflow에 대해 이야기하면서 TF-IDF를 스쳐 지나듯 이야기했었습니다.
그리고 Downstream Task에 대해서도 스쳐 지나가듯 이야기했습니다.
정확히 이야기하면 다뤘지만 너무 초기의 이론에 대해서만 이야기했었습니다.
그리고 오늘 수업 시간에 꽤 진지하게 다뤄진 이야기이기 때문에 TF-IDF와 STS에 대해 짚고 넘어가겠습니다.
TF-IDF의 자세한 내용은 이 글을 참고했습니다.
TF-IDF는 간단히 말하면 많은 정보들(문서, 단어)를 고려해 단어들마다 중요한 정도를 가중치 주는 법입니다.
TF-IDF는 문서의 유사도를 구하는 작업, 검색 시스템에서 검색 결과의 중요도를 정하는 작업 등에 쓰입니다.
이번 글에서 STS(텍스트 의미적 유사성)을 구현하는 코드를 볼 거기 때문에 TF-IDF를 먼저 알아야 합니다.
TF는 Term Frequency의 준말로 단어의 빈도를 말하고
IDF는 Inverse Document Frequency의 준말로 역문서 빈도를 말합니다.
(이따가 이야기하겠지만 IDF는 단순히 문서 빈도의 역수가 아닙니다.)
그래서 TF-IDF는 단어의 빈도와 역문서 빈도를 곱한 값으로 볼 수 있습니다.
TF-IDF를 이해하려면 우선 DTM(Document-Term Matrix)에 대해 알아야 합니다.
DTM은 저번 시간에 이야기한 BoW에서 다른 문서들의 BoW를 결합한 표현 방법이라고 보면 됩니다.
이번 글의 주제는 DTM이 아니니까 간단한 예를 보고 넘어가겠습니다.
문서1 : 먹고 싶은 사과
문서2 : 먹고 싶은 바나나
문서3 : 길고 노란 바나나 바나나
문서4 : 저는 과일이 좋아요
위처럼 4개의 문서가 있을 때 DTM은 아래처럼 됩니다.
| 과일이 | 길고 | 노란 | 먹고 | 바나나 | 사과 | 싶은 | 저는 | 좋아요 | |
| 문서1 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 0 | 0 |
| 문서2 | 0 | 0 | 0 | 1 | 1 | 0 | 1 | 0 | 0 |
| 문서3 | 0 | 1 | 1 | 0 | 2 | 0 | 0 | 0 | 0 |
| 문서4 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 |
각 문서에서 등한 단어의 빈도를 행렬으로 표기한 것으로 볼 수 있습니다.
각 문서가 행이 되므로 문서들을 서로 비교할 수 있다는 점에서 의의가 있다고 합니다.
TF는 간단하게 DTM에 입력되어 있는 숫자라고 보면 됩니다.
예를 들면 문서 4의 "과일이"의 TF는 1입니다.
그리고 DF는 특정 단어가 몇 개의 문서에서 출현했는지를 표현합니다.
특정 단어가 하나의 문서에 몇 번 출현했는지는 중요하지 않습니다.
예를 들면 "먹고"의 DF는 "먹고"가 문서 1과 문서 2에서 출현하기 때문에 2입니다.
IDF는 DF의 역수와 비슷하지만 역수는 아닙니다.

참고로 n은 문서의 총 개수고 로그는 보통 자연로그를 사용합니다.
자연로그는 로그의 밑으로 e(2.718281...)을 쓰는 로그입니다.
IDF의 식에서 주목해야 할 것은 log와 분모에 1이 들어가는 것입니다.
idf에 로그를 취하는 이유는 문서의 총개수가 한없이 큰 수가 되면
idf의 값이 한없이 커지기 때문입니다.
특히 하나의 문서에만 쓰이는 희귀 단어가 쓰일 시 엄청난 가중치가 부여될 수 있습니다.
그리고 분모에 1을 더하는 이유는 분모가 0이 되는 상황을 방지하기 위해서입니다.
종합하면 TF-IDF는 "입니다" "습니다" 같이 매 문서에서 등장하는 단어들의 중요도는 낮추고
그 문서에서만 등장하는 희귀 단어는 중요도를 높이는 임베딩 방법입니다.
위에서 예를 들어 이야기한 DTM의 IDF를 구하면 아래 표와 같습니다.
| 단어 | IDF |
| 과일이 | ln(4/(1+1)) = 0.693147 |
| 길고 | ln(4/(1+1)) = 0.693147 |
| 노란 | ln(4/(1+1)) = 0.693147 |
| 먹고 | ln(4/(2+1)) = 0.287682 |
| 바나나 | ln(4/(2+1)) = 0.287682 |
| 사과 | ln(4/(1+1)) = 0.693147 |
| 싶은 | ln(4/(2+1)) = 0.287682 |
| 저는 | ln(4/(1+1)) = 0.693147 |
| 좋아요 | ln(4/(1+1)) = 0.693147 |
종합하여 위에서 구한 TF와 IDF를 곱하면 아래와 같이 나옵니다.
| 과일이 | 길고 | 노란 | 먹고 | 바나나 | 사과 | 싶은 | 저는 | 좋아요 | |
| 문서1 | 0 | 0 | 0 | 0.287682 | 0 | 0.693147 | 0.287682 | 0 | 0 |
| 문서2 | 0 | 0 | 0 | 0.287682 | 0.287682 | 0 | 0.287682 | 0 | 0 |
| 문서3 | 0 | 0.693147 | 0.693147 | 0 | 0.575364 | 0 | 0 | 0 | 0 |
| 문서4 | 0.693147 | 0 | 0 | 0 | 0 | 0 | 0 | 0.693147 | 0.693147 |
그리고 두 번째로 STS(Semantic Textual Similarity)는 두 문장의 유사성을 판단하는 downstram task입니다.
보통 sts는 두 가지로 나뉩니다.
- Binary Classification : 두 문장의 의미가 같은가 --> F1 Score로 평가
- Regression : 두 문장의 의미가 얼마나 같은가(유사도) --> Pearson Coefficient로 평가
그러면 두 문장의 의미가 같은 지의 여부를 예측할 때 어떻게 분류할지 알아봅니다.
만약 Logistic Regression을 분류 모델로 사용하면, 유사도를 계산해서 특정값을 기준으로 낮은지 높은 지를 구분합니다.
유사도는 보통 Jaccard Similarity와 Cosine similarity를 이용해서 구합니다.
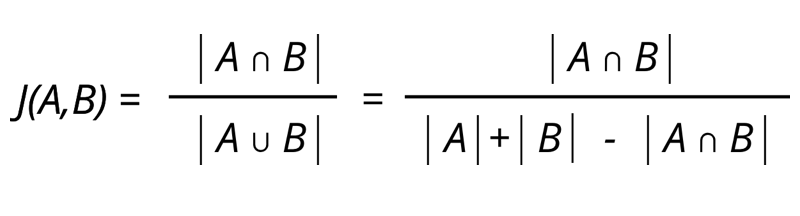

그러면 Logistic Regression의 특정값(threshold) sms training data를 기준으로 최적의 threshold를 찾아서 사용합니다.
마지막으로 코랩에서 Scikit-Learn의 TF-IDF Vectorizer를 사용해 STS를 구현해봅니다.
아래 코드는 AI 교육계의 거장 김용담 선생님이 End-to-End로 짠 코드입니다.
일단 STS 실습 예제의 데이터는 KLUE에서 제공한 데이터를 사용했습니다.
import json
def read_json(path):
with open(path) as f:
data = json.load(f)
return dataKLUE에서 제공한 데이터는 json 형태로 되어있기 때문에
json 모듈을 불러오고 json파일을 불러오는 함수를 만듭니다.
data_path = "/content/drive/MyDrive/Colab Notebooks/data/klue-sts-v1.1/"
train = read_json(data_path + "klue-sts-v1.1_train.json")
test = read_json(data_path + "klue-sts-v1.1_dev.json")구글 드라이브 내에 파일이 존재하는 폴더의 위치를 변수 지정하고
train, test 데이터들을 위에서 만든 read_json 함수로 불러옵니다.
type(train)
type(train[1])
train[1]
# list
# dict
# {'annotations': {'agreement': '5:0:0:0:0:0',
'annotations': [0, 0, 0, 0, 0],
'annotators': ['14', '12', '08', '10', '13']},
'guid': 'klue-sts-v1_train_00001',
'labels': {'binary-label': 0, 'label': 0.0, 'real-label': 0.0},
'sentence1': '위반행위 조사 등을 거부·방해·기피한 자는 500만원 이하 과태료 부과 대상이다.',
'sentence2': '시민들 스스로 자발적인 예방 노력을\xa0한 것은 아산 뿐만이 아니었다.',
'source': 'policy-sampled'}데이터를 불러온 train, test의 데이터 타입은 list입니다.
그리고 각 원소의 데이터 타입은 dict입니다.
print(len(train))
print(len(test))
#11668
#519
1. 유사도 분석할 문장 둘과 비슷한 문장 여부를 나타낸 레이블을 한 행으로 하는 DataFrame을 만듭니다.
import pandas as pd
def make_dataset(data):
sentences1 = []
sentences2 = []
labels = []
df = pd.DataFrame()
for temp in data:
sentences1.append(temp["sentence1"])
sentences2.append(temp["sentence2"])
labels.append(temp["labels"]["binary-label"])
df["sentences1"] = sentences1
df["sentences2"] = sentences2
df["is_duplicate"] = labels
return df판다스 모듈을 불러오고 불러온 데이터(json에서 list로 변환된) 원소의
sentence1, sentence2, label 중 binary-label를 dataframe으로 만들어 주는 함수를 만듭니다.
train_df = make_dataset(train)
test_df = make_dataset(test)
train_df.head()| sentences1 | sentences2 | is_duplicate | |
|---|---|---|---|
| 0 | 숙소 위치는 찾기 쉽고 일반적인 한국의 반지하 숙소입니다. | 숙박시설의 위치는 쉽게 찾을 수 있고 한국의 대표적인 반지하 숙박시설입니다. | 1 |
| 1 | 위반행위 조사 등을 거부·방해·기피한 자는 500만원 이하 과태료 부과 대상이다. | 시민들 스스로 자발적인 예방 노력을 한 것은 아산 뿐만이 아니었다. | 0 |
| 2 | 회사가 보낸 메일은 이 지메일이 아니라 다른 지메일 계정으로 전달해줘. | 사람들이 주로 네이버 메일을 쓰는 이유를 알려줘 | 0 |
| 3 | 긴급 고용안정지원금은 지역고용대응 등 특별지원금, 지자체별 소상공인 지원사업, 취업성공패키지, 청년구직활동지원금, 긴급복지지원제도 지원금과는 중복 수급이 불가능하다. | 고용보험이 1차 고용안전망이라면, 국민취업지원제도는 2차 고용안전망입니다. | 0 |
| 4 | 호스트의 답장이 늦으나, 개선될 것으로 보입니다. | 호스트 응답이 늦었지만 개선될 것으로 보입니다. | 1 |
2. 불러온 데이터를 train, validation set으로 분할합니다.
def pair_to_sequence(data):
return list(data["sentences1"]) + list(data["sentences2"])
def Vectorizer(vectorizer, sentences):
vec = vectorizer.transform(sentences)
print(f"Shape of whole sentences after TF-IDF vectorizer: {vec.shape}")
length = int(len(sentences)/2)
vec1 = vec[:length]
vec2 = vec[length:]
print(f"Shape of TF-IDF vectors for sentences1 : {vec1.shape}\nShape of TF-IDF vectors for sentences2: {vec2.shape}")
return vec1, vec2데이터 프레임의 "sentences1" 칼럼과 "sentences2"칼럼을 리스트로 만들어
하나의 리스트로 만드는 함수(pair_to_sequence)를 만듭니다.
그리고 리스트의 형식으로 된 sentence들을 TfidVectorize 시키고 반으로 나눠
vec1, vec2를 return 하는 Vectorizer함수를 만듭니다.
vec1은 sentences1 데이터를, vec2는 senteces2 데이터를 포함하고 있습니다.
3. TFIDF를 Vectorizer.fit()할 때, train set에 있는 모든 sen1, sen2를 합쳐 학습합니다.
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import train_test_split
X = train_df.drop("is_duplicate", axis=1)
y = train_df.is_duplicate
# train, validation set 분리
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=42)
print(X_train.shape, X_val.shape, y_train.shape, y_val.shape)
# TFIDF 학습시킬 input sequence 준비
vectorizer = TfidfVectorizer()
train_sentences = pair_to_sequence(X_train)
vectorizer.fit(train_sentences)
val_sentences = pair_to_sequence(X_val)
train_vec1, train_vec2 = Vectorizer(vectorizer, train_sentences)
val_vec1, val_vec2 = Vectorizer(vectorizer, val_sentences)사이킷런 모듈 TfidfVectorizer아 train_test_split을 불러옵니다.
X와 y값으로 변수 지정하고 train, test set으로 분리합니다.
그리고 위에서 만든 함수를 활용해 데이터들을 임베딩(벡터화)합니다.
여기서 vectorizer.fit(train_sentences)은 변환되는 공간이 정의되는 것을 말합니다.
4. pair 되는 문장들의 유사도를 계산합니다.
from sklearn.metrics.pairwise import paired_cosine_distances
# Note : cosine distance = 1 - cosine similarity
train_dists = paired_cosine_distances(train_vec1, train_vec2)
val_dists = paired_cosine_distances(val_vec1, val_vec2)
print(train_dists.shape, val_dists.shape)
#(9334,) (2334,)paired_cosine_distances 모듈을 불러와 유사도를 구합니다.
cosine distance 역시 cosine similarity와 같이 값이 작을수록 의미가 유사하다고 볼 수 있습니다.
5. 계산한 유사도를 threshold 값을 기준으로 0이나 1로 변환합니다.
import numpy as np
def distance_to_label(distances, threshold=0.5):
preds = np.zeros(distances.shape[0])
preds[distances<threshold] = 1
return preds예측한 cosine distance가 threshold보다 작을 시에
두 문장의 의미가 유사하다고 1로 레이블링 하는 함수를 만듭니다.
threshold = 0.5
train_preds = distance_to_label(train_dists, threshold)
val_preds = distance_to_label(val_dists, threshold)train dataset의 코사인 거리와 validation dataset의 코사인 거리를 변수 지정합니다.
6. Accuracy와 F1-score를 측정합니다.
from sklearn.metrics import accuracy_score
train_acc = accuracy_score(y_train, train_preds)
val_acc = accuracy_score(y_val, val_preds)
print(f"Accuracy for training: {train_acc:.4f} and for validation: {val_acc: .4f}")
# Accuracy for training: 0.6180 and for validation: 0.6547실제 값과 예측값으로 accuracy score를 구합니다.
from sklearn.metrics import f1_score
train_f1 = f1_score(y_train, train_preds)
val_f1 = f1_score(y_val, val_preds)
print(f"Accuracy for training: {train_acc:.4f} and for validation: {val_acc:.4f}")실제 값과 예측값으로 f1_score를 구합니다.
X_test = test_df.drop("is_duplicate", axis=1)
y_test = test_df["is_duplicate"]
print(X_test, y_test)
# tfidf 학습시킬 input sequence 준비
test_sentences = pair_to_sequence(X_test)
test_vec1, test_vec2 = Vectorizer(vectorizer, test_sentences)앞에서 train데이터에 했던 작업을 똑같이 test 데이터에 해줍니다.
X_test, y_test을 구분해주고 test 데이터를 Vectorizer로 벡터화합니다.
test_dists = paired_cosine_distances(test_vec1, test_vec2)
print(test_dists.shape)
# (519,)test dataset의 코사인 거리를 구하고 shape을 출력합니다.
preds = distance_to_label(test_dists, threshold)
test_acc = accuracy_score(y_test, preds)
print(f"Accuracy for test: {test_acc:.4f}")
test_f1 = f1_score(y_test, preds)
print(f"F1 score for test: {test_f1:.4f}")
# Accuracy for test: 0.5376
# F1 score for test: 0.1111실제값과 예측값을 비교해 Accuracy Score와 F1 Score를 출력합니다.
7. train set에 대해 optimal threshold를 찾습니다.
#array for finding the optimal threshold
def find_optimal_threshold(y_true, y_pred, step=0.001):
thresholds = np.arange(0.0, 1.0, step)
fscore = np.zeros(shape=len(thresholds))
print(f"Total {len(thresholds)} steps between 0 to 1 for each {step}")
# Fit the model
for index, threshold in enumerate(thresholds):
# Corrected distances
y_pred_prob = (y_pred < threshold).astype('int')
# Calculate the f-score
fscore[index] = f1_score(y_true, y_pred_prob)
# Find the optimal threshold
index = np.argmax(fscore)
thresholdOpt = round(thresholds[index], ndigits=4)
fscoreOpt = round(fscore[index], ndigits=4)
print('Best Threshold: {} with F-Score: {}'. format(thresholdOpt, fscoreOpt))
# Plot the threshold tuning
df_threshold_tuning = pd.DataFrame({'F-score':fscore,
'Threshold':thresholds})
return thresholdOpt, df_threshold_tuningthreshold값을 step만큼 아주 조금씩 옮기면서 최적의 F1 score를 출력하는 threshold를 구하기 위해 함수를 정의합니다.
그리고 threshold가 바뀔 때마다 바뀌는 F1 Score를 기록해
f1-score와 threshold를 column으로 하는 df_threshold_tuning으로 출력합니다.
step = 0.001
opt_threshold, train_threshold_df = find_optimal_threshold(y_train, train_dists, step)
# Total 1000 steps between 0 to 1 for each 0.001
# Best Threshold: 0.882 with F-Score: 0.818step을 0.001로 정의했을 때의 최적의 threshold와 그때의 f1-score를 확인합니다.
train_threshold_df.plot()matplotlib으로 train_threshold_df를 그래프로 표현해봅니다.
return으로 나온 threshold(0.882)에서 제일 좋은 F1_score를 기록합니다.

print(f"===Apply optimal threshold {opt_threshold}===")
val_preds = distance_to_label(val_dists, opt_threshold)
preds = distance_to_label(test_dists, opt_threshold)
opt_val_acc = accuracy_score(y_val, val_preds)
opt_test_acc = accuracy_score(y_test, preds)
print(f"Accuracy for validation: {opt_val_acc:.4f}")
print(f"Accuracy for test: {opt_test_acc:.4f}")
opt_val_f1 = f1_score(y_val, val_preds)
opt_test_f1 = f1_score(y_test, preds)
print(f"F1 score for validation: {opt_val_f1:.4f}")
print(f"F1 score for test: {opt_test_f1:.4f}")
print("\n*** Performance Gain: %.4f ***" % (opt_test_f1 - test_f1))
# ===Apply optimal threshold 0.882===
# Accuracy for validation: 0.7866
# Accuracy for test: 0.4451
# F1 score for validation: 0.8022
# F1 score for test: 0.4857
# *** Performance Gain: 0.3746 ***최적의 threshold를 적용했을 때 나오는 validation dataset과 test dataset의 Accuracy와 f1-score를 출력합니다.
test dataset은 validation dataset에 비해 점수가 굉장히 저조한 걸 알 수 있습니다.
'AI > K-Digital Training' 카테고리의 다른 글
| 032. NLP 미니 프로젝트 후기 (0) | 2021.10.26 |
|---|---|
| 031. 코로나 백신 2차접종후 딥러닝 학습 후기.. (0) | 2021.10.15 |
| 029. NLP Workflow를 깜빡했다. (2) | 2021.10.07 |
| 028. Hello NLP(Natural Language Processing)! (0) | 2021.10.07 |
| 027. 딥러닝과 주식투자의 연계성에 대한 인문학적 고찰 (0) | 2021.10.04 |